
To find a harmonized European solution for testing automated road transport, the HEADSTART project has defined a testing and validation methodology. By cross-linking the three test instances, virtual simulation testing, proving ground testing and X-in-the-loop based testing, as well as looking into field testing, tests to validate safety and security performance the needs for a feasible validation framework for different user groups shall by satisfied. When it comes to the validation and verification of automated driving functions, sample calculations show that a huge number of driving kilometers in field tests would be necessary. This is not feasible for modern automated driving functions. Therefore, the HEADSTART methodology builds upon a scenario-based data-driven approach by abstracting real-world drives to scenarios utilizing large scenario-databases.
A primary goal of the HEADSTART methodology is to establish a common and harmonized approach for the validation and verification of automated driving functions within Europe, as well as internationally. Thus, the international communication is a key aspect of HEADSTART. Finally, the HEADSTART methodology not only harmonizes existing approaches and databases from well-known projects like the PEGASUS Family (e.g. PEGASUS, VVMethods and SetLevel4To5), MOOVE/MOSAR, L3Pilot, TNO StreetWise or Ensemble but also tries to include so-called key-enabling-technologies selected by HEADSTART; Communication V2X, Positioning and Cyber-security.
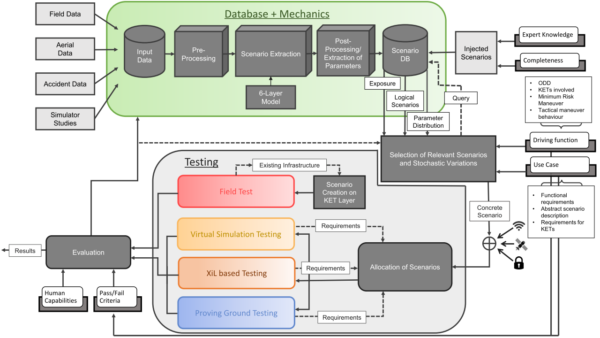
The HEADSTART methodology is illustrated in Figure 1. The HEADSTART methodology is interfacing with scenario databases, which are currently established at different initiatives. Therefore, input data from various sources is required. These sources can be among others field operational tests, naturalistic driving studies, infrastructure data or drones/UAV datasets, like the well-known highD and inD datasets from Aachen or Argoverse from Miami and Pittsburgh. Within common databases, conflating large amounts of data, logical driving scenarios are extracted. This is an abstraction step to analyse real-world traffic and to gather statistical information to build up a parameter space. These scenario databases and their respective scenarios and toolchains are a key element of the methodology. Since, the completeness of these databases may not be sufficient in early stages, injected scenarios from expert knowledge or based on ontology creations may be another input.
The output of such scenario databases has to include logical scenarios with their respective statistics, including the exposure and a parameter distribution. The required scenarios are queried based on the driving function including the ODD, the use case and previous evaluation results. In this step, concrete scenarios are computed from the logical scenario input by selecting relevant scenarios and varying the parameters within the giving parameter space. Finally, these concrete scenarios are enhanced by three key-enabling-technologies (KETs), namely cybersecurity, communication/V2X and positioning. Especially, cyber-security needs a more detailed treatment due to its specific character. Therefore, a specialized method is defined and is input directly to the methodology.
Subsequently, concrete scenarios need to be allocated among various test instances, reaching from pure simulation over different X-in-the-Loop testing methods (e.g. Hardware-in-the-Loop, Vehicle-in-the-Loop) to proving ground testing. The allocation toolchain block is endeavoured to test in the simulation due to high efficiency. However, some scenarios might need further validation and thus need to be allocated to more real-world components, eventually being rolled out the proving ground. The testing methods are based on open standards like OpenSCENARIO and OpenDRIVE, but also ASAM Open Simulation Interface to support interoperability and co-simulations. Field testing takes a special role in HEADSTART, since scenarios on the open road cannot be staged and thus a roll out is not easily possible. However, there are ongoing activities taking a deeper look into field testing.
Finally, results from the testing are evaluated and can provide a basis for the safety argumentation for the driving function. Moreover, results are fed back into the toolchain by providing the results to the scenario database but also to the selection of relevant scenarios. This is necessary to efficiently cover the necessary parameter space.
This blog post on the HEADSTART methodology is by Nicolas Wagener (ika).
Nicolas Wagner is working as scientific researcher at the Institute of Automotive Engineering at the RWTH Aachen University for over three years. He studied computer science and received his master degree in 2011 from RWTH Aachen. His research focus is currently based on automated driving, simulation, verification and validation of automated driving functions.